In the earlier post we have learnt about Radius Access Request/Response verification, and in this post we will learn about how the radius clients create Radius Accounting packet and we will verify the radius accounting packet with wireshark.
This post will be useful if we want to simulate the Radius Accounting against and to simulate the data usage for QA purpose.
Radius Accounting will start once the user is authorized. Accounting packet consists of the session info (ex : How much data is used by the client, session time etc). The primary purpose of this data is that to bill the users based on the usage and data is also commonly used for general network monitoring.
Interim Update records may be sent by the NAS to the RADIUS server, to update it on the status of an active session periodically based on the accounting interval.
There are different Account Status types available in the RADIUS (Ex: Start,Stop,Interim Update, Accounting-On,Accounting-Off etc).
Radius Accounting Request Decryption
Here we will take the example for the interim update and we will verify the radius accounting packet. Verification will be same for Start and Stop and other Account Status Types as well.

Below is the Figure 2 is Radius Accounting packet captured in wireshark. Few important attributes are marked in the Figure 2 .
Input octets/output octets states that number of octets sent and received on an interface, it will be used to track the data used by the client for billing purpose. Session time states that how long the session is active.
Authenticator in the below figure is the md5 authenticator for the full frame.
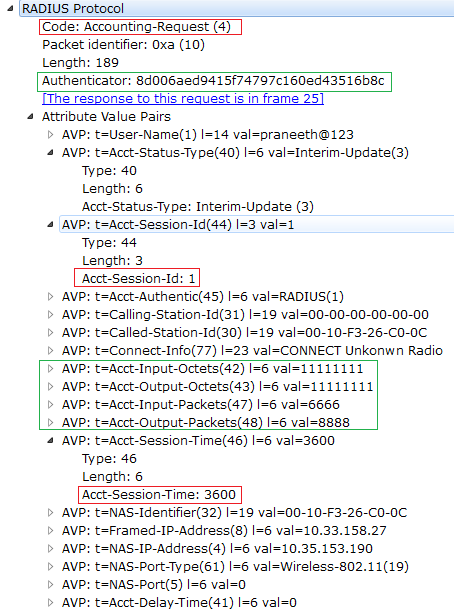
Now we will verify the Accounting request shown the above capture.
Below is the input to the Md5 algorithm in Radius Accounting Request.
Accounting Request = Md5 (Code + Identifier + Length + 16 zero octets + request attributes + shared secret
- Code
- ID
- Length
- 16 zero octets (we should replace authenticator while verifying)
- Attributes
- Secret (hex)
The final hex stream is shown below, and it will be sent to the md5 algorithm. Execute the below line in any linux terminal, you will be able to generate the authenticator.
echo -n '040a00bd00000000000000000000000000000000010e7072616e65657468403132332806000000032c03312d06000000011f1330302d30302d30302d30302d30302d30301e1330302d31302d46332d32362d43302d30434d17434f4e4e45435420556e6b6f6e776e20526164696f2a0600a98ac72b0600a98ac72f0600001a0a3006000022b82e0600000e10201330302d31302d46332d32362d43302d304308060a219e1b04060a2399be3d06000000130506000000002906000000007072616e65657468' | xxd -r -p | openssl dgst -md5
Observe the output of a command , it matches with the authenticator we see in the wireshark.
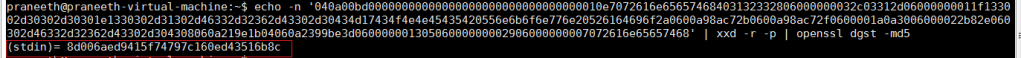
This is how the Radius Accounting Requests are constructed.
Radius Accounting Response Decryption
Till now we have learnt the Radius Accounting Request Construction. Now we will learn about the Radius Accounting Responses construction and verification.
Note that input to the MD5 program is little different in Radius Accounting Response frames.
Below Figure 4, shows the Radius Accounting-Response Frame.
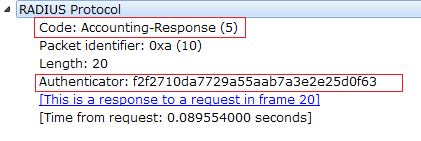
Below is the input to the Md5 algorithm in Radius Accounting Response Frame.
We will get RequestAuth from the Radius Accounting Request frame.
Below is the input to the Md5 algorithm in Radius Accounting Response frame.
Accounting-Response Authenticator = MD5(Code+ID+Length+RequestAuth+Attributes+Secret)
- Code
- ID
- Length
- RequestAuth (Radius Accounting request Authenticator, get it from sniffer cap on Accounting request)
- Attributes (If any)
- Shared Secret (hex)
Based on the sniffer captures, Below is the data that we need to send to the Md5 program.
- Code = 05
- ID= 01
- Length=0014
- Request Auth = 8d006aed9415f74797c160ed43516b8c (Accoutning Authenticator)
- REQ ATTRIBUTES = IF ANY
- Secret= 7072616e65657468 (Hex to Ascii = praneeth)
Now concatenate all the data and send the hex input to the md5 program. We will be able to generate the authenticator for Accounting response frame.
Execute the below command in any linux terminal, you will be able to generate the md5 authenticator for the Radius Accounting-response frame.
echo -n '050a00148d006aed9415f74797c160ed43516b8c7072616e65657468' | xxd -r -p | openssl dgst -md5
Observe that the output of a md5 program matches with the authenticator seen in the Radius Accounting-Response Frame.
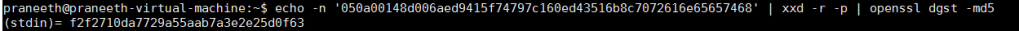
This is how the Radius constructs the Radius Accounting Packets.
These radius frames still uses MD5 and it is less secure. If we want to provide the security for the Radius Frames, they should be sent in a Radsec tunnels.
In the next post we will learn about the Radsec proxy and we will send the classic Radius UDP data inside a TLS tunnels (Radsec).
